数据结构与算法Week4——KMP算法
字符串模式匹配——KMP算法
本周学习了第四章——字符串,其实,基本操作(查找、截取、连接、复制……)早在大一上C语言就已经学过了;而在大一下的C++中,string类也提供了很方便的库函数,所以,我们这节课的重点是KMP算法,这是我们目前课上学的第一个有难度的算法。
KMP算法确实有点“反常识”,导致它抽象而难于理解。我用这篇文章把自己理解的思想记录下来,辅以图解来直观记忆。这些图都是我用draw.io绘制的,转载请注明出处。
什么是KMP算法
KMP算法主要是字符串匹配问题的优化。
大部分时候,我们采用的字符串匹配都是O(n*m)的,也就是说,从头到尾遍历主串,以每个字符为开头尝试匹配,如果失配,就回溯到开头的下一个位置继续尝试,直到找到模式串或者遍历完主串。显然,最坏的情况是对主串的每一个位置,都可以部分匹配模式串而只差一个,比如在0000000000000000中找000001,此时,一共要进行n*m次比较。
然而,有这样的一种思路:在我们匹配了一段发现失配时,失配前的那一段是匹配的,也称主串和模式串部分匹配。在上面的例子中,我们匹配了前五个0之后,发现第六个1不匹配,如果按照朴素的方法,就是从s[1]开始重复此过程,然而,当i移动到1时,我们已经知道自此往后的五个都是0(是通过前面所说的的部分匹配得到的),那么我们可以直接比较第6位,如果是1,就匹配成功,否则就再将i向前移动一个。我作了个图,来体现匹配次数的差异。箭头指向的位置是需要判断的地方,可以推知,在这里,每次移动i,都仅仅需要多判断那个失配的位置而已,减少了大量的重复判断。
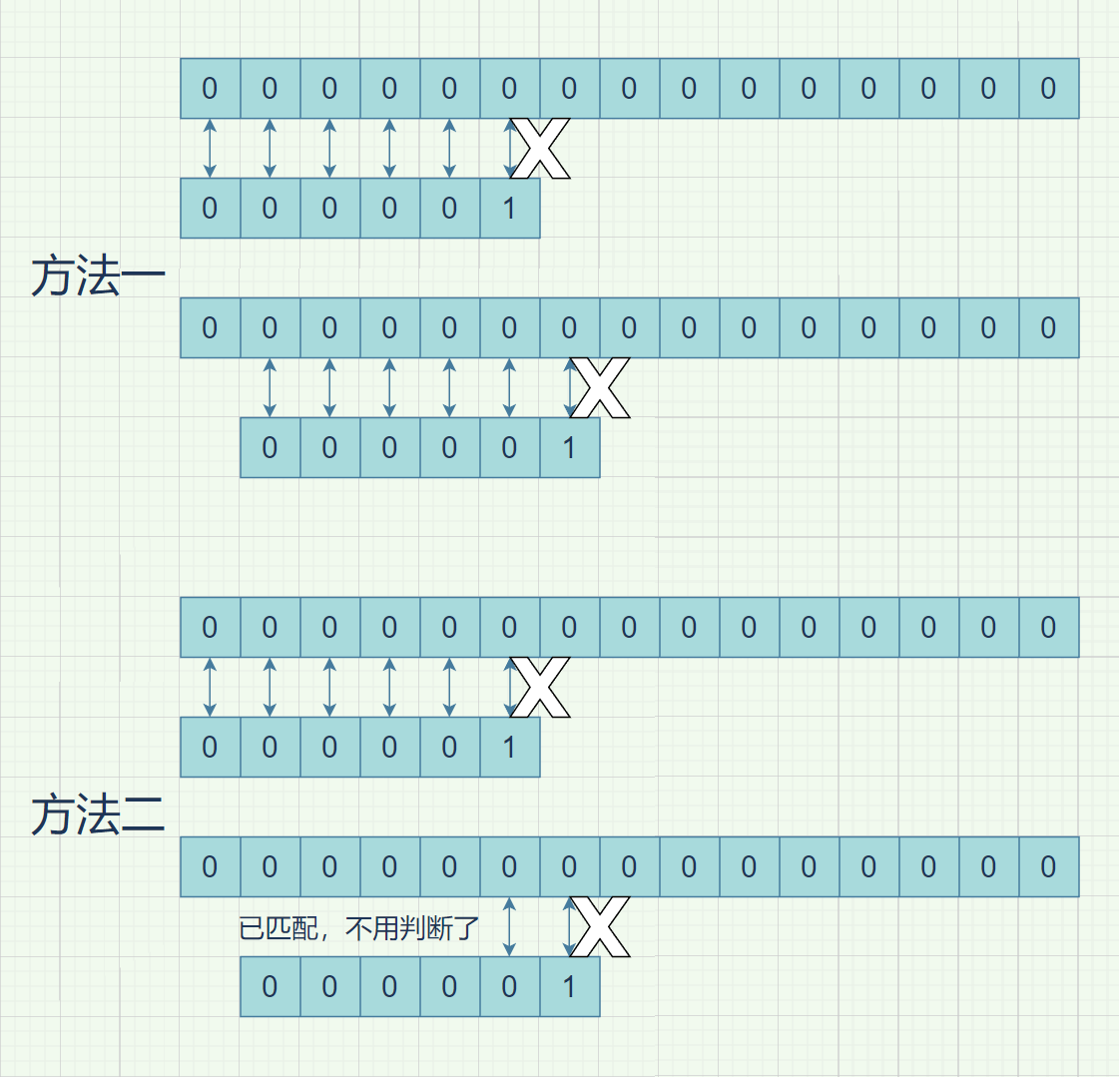
上面是有大部分一样字符的情况。这其实也是kmp算法最有优势的情况。那么,对于一般的情况,匹配过程又是怎么样的呢?
KMP算法的原理
不失一般性,作出下图。从主串的第一个橙色块开始,与模式串匹配,直到倒数第三个失配。同时,注意到,模式串中已匹配的部分,前面的红色块与后面的红色块相同,那么,容易推知,最后三个橙色块也与前面的红色块相同,如图所示。也就是说,在我们需要判断它们时,可以利用这个信息减少判断次数。
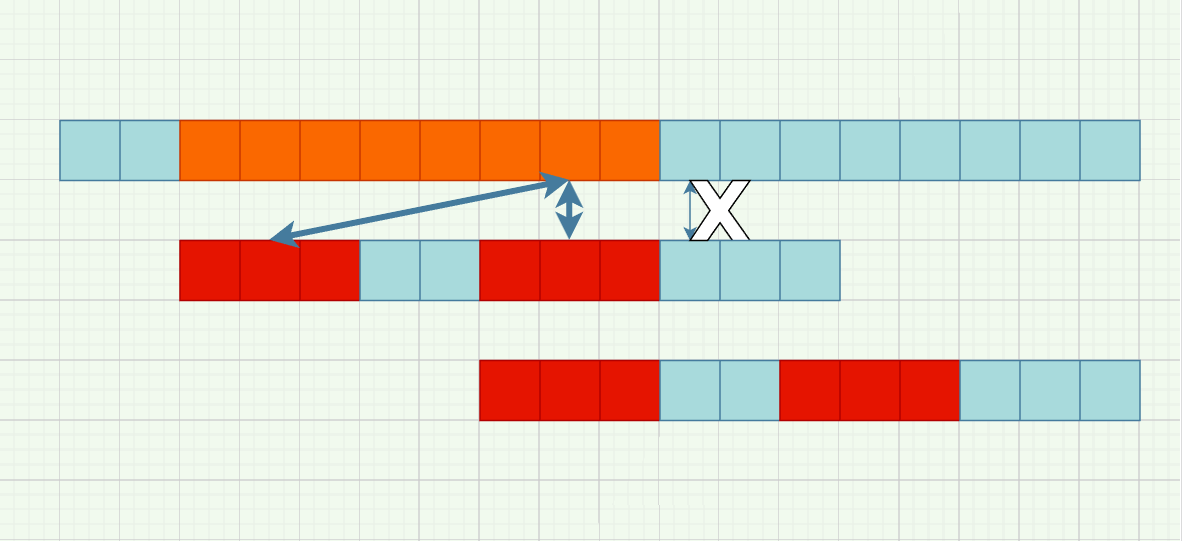
接下来,是最重要的一点。我在摸索的过程中,看了好几本教材的表述,以及很多的文章,很少有讲清楚这里的。大概是被算法中的i永远不回溯给限制住了。
这里,我将用和朴素的匹配方法类似的思想来解释KMP中神奇的操作。首先,我们先说说算法的目的:如果能在主串中找到模式串,就返回主串中第一次匹配成功的初始位置,否则返回-1。根据这个目标,当我们发现失配时,就将起始点移动到下一个可能匹配成功的位置,在朴素匹配中,也就是起始点的下一个位置。然而,依据上面的信息,我们可以把起始点移动地更远一些。那么,需要解决的问题就是:下一个可能起始点到底在哪!!!根据部分匹配的信息,我们可以得到可能的起始点必须满足的条件。请看图
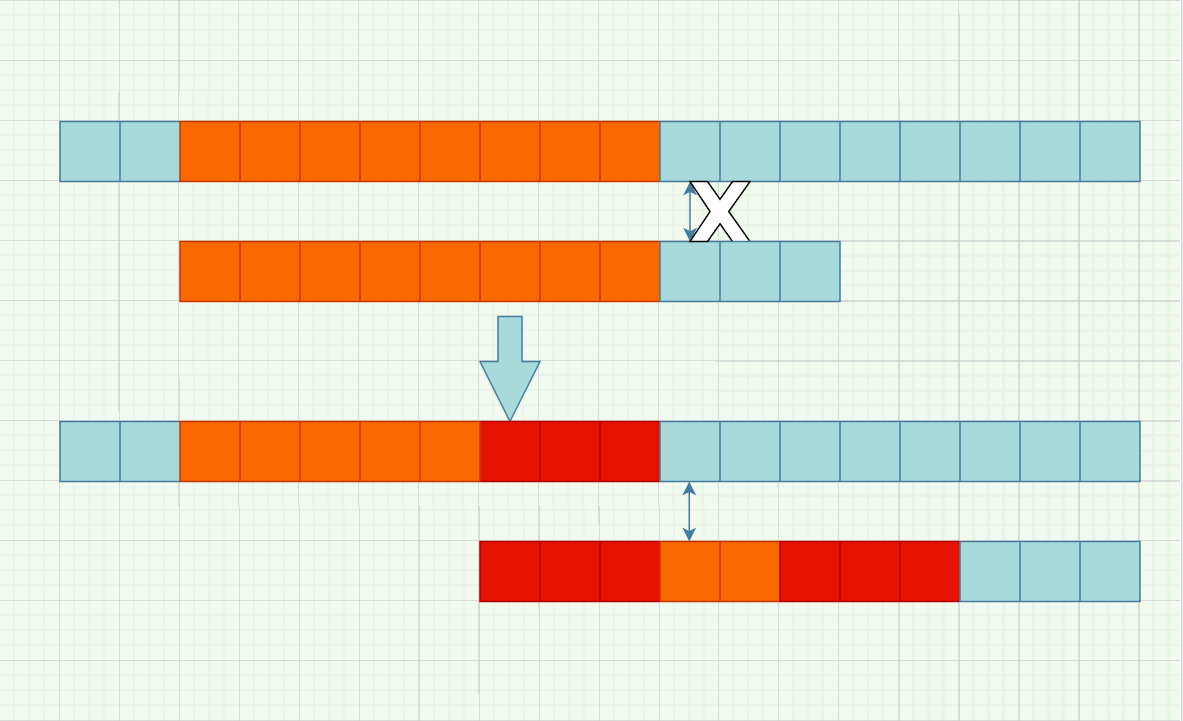
在已知部分匹配的前提下,假如新的起始点在匹配过的内部,比如箭头所示位置,成功匹配的前提是满足如图红色的相等关系。可以看出,这就是匹配成功的部分的前缀和后缀相等的部分。那么,如果我们找到了最长的公共前后缀,不就也找到了下一个可能的起始点了嘛!此外,起始点确定后,中间部分也不用判断了(必然已经匹配),可以直接从失配的位置开始判断,体现在代码上就是主串的指针不回溯,而模式串的指针回溯到待匹配的位置(由于i-j就是起点,也就相当于右移了起点)。
所谓待匹配的位置又该怎么求呢?根据上面的分析,next[j]就应该是j前面最长公共前后缀的下一个位置。由于这个结果只与模式串有关,不管主串是什么,我们都可以把模式串在某处失配时应当跳到的位置求出来。所以,可以对模式串进行预处理,求出所有位置失配的下一跳,储存在一个next数组中。
如何求next数组呢?重申一下,next[i]应当是在i前面的序列的最长公共前后缀的后一个位置,比如说,abcabeabd,如果在e处失配,由于abcab的最长公共前后缀是ab,那么应该跳到c继续尝试匹配。我们可以用一种巧妙的方法求出next数组,也就是用模式串自身进行匹配,但是要注意主串从第二个位置开始尝试(之所以去掉第一个位置,是因为前后缀不能相同,否则会出现停在原地的情况,去掉第一个元素就保证了后缀不会是前缀),和上面的过程类似,具体步骤见下一节。
KMP代码解析
匹配部分的具体做法是:从头开始,正常匹配,i和j同步前进,当出现失配时,i不动,移动j到下一个待匹配的位置,继续上面的过程,直到匹配成功或者模式串的每个前缀都匹配不上i的位置,此时,称i完全失配,++i,从下一个位置开始重新匹配。可以写出匹配部分的代码如下。
1 | s1=" "+s1;//添加头部哨兵,真正的字符串从i=1开始,作用在后面详述 |
求解next数组的具体做法是,先将next[1]=0,代表一个不能达到的位置,然后让i从1开始,j从0开始,进行匹配,正常匹配时,i和j同时步进,并记录下一个位置的next值(每次成功匹配,必然都是下一个位置的最长前后缀),如果当前位置完全失配,就将它的next置为1,也就是从头开始匹配。其余操作和上面匹配过程是一样的(毕竟求next数组也是在模式匹配嘛)。具体代码如下
1 | vector<int> next(s2.size());//添加哨兵节点的过程省略 |
next数组的求解要更难理解一点,所以用图解来表示一下具体步骤,仍是用abcabeabd举例,已添加了哨兵节点

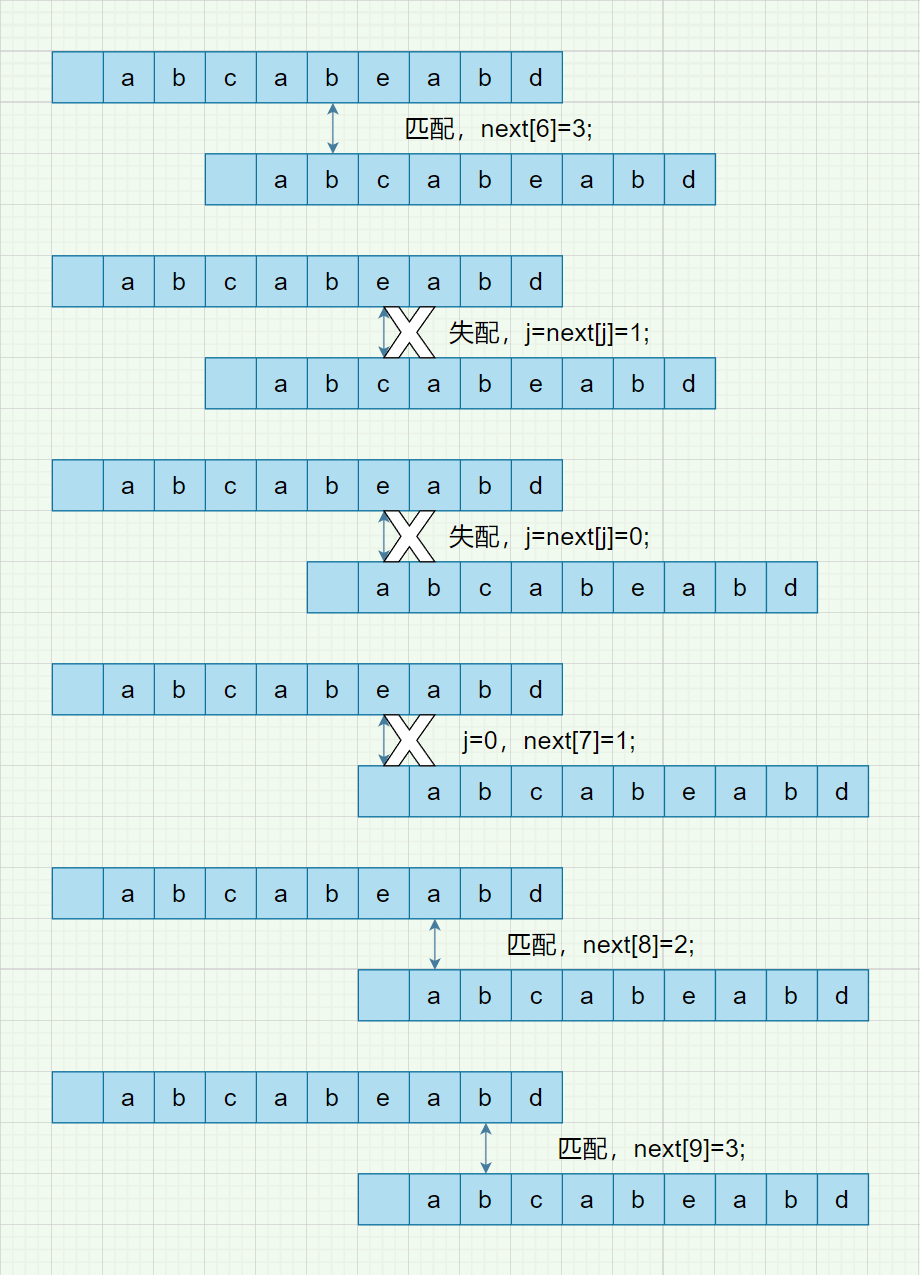
最终的next数组就是[0 0 1 1 1 2 3 1 2 3],其中next[0]=next[1]=0,是预先设定的。
如果还是有点不理解,可以自己试着写一个模式串推推看它的next数组,多想一想也就理解了。
最终代码
最后,以完整的KMP算法做结尾吧,写了这么多遍,背都背下来了😂😂
1 |
|
这篇文章或许还不完善,如果我对KMP有了新的理解,一定会来更新。
10.2更新——KMP应用题
KMP看上去高深而又鸡肋,或许在字符串比较中能更快些(不过也是在n>>m时计算next数组的消耗才是值得的),但在算法竞赛中似乎就显得很鸡肋了,毕竟自带的find库函数就绝对够用了。不过神奇的是,就在这周的周赛中,我用上了KMP。
是leetcode2430. 对字母串可执行的最大删除数,题目如下:
给你一个仅由小写英文字母组成的字符串 s 。在一步操作中,你可以:
- 删除 整个字符串
s,或者 - 对于满足
1 <= i <= s.length / 2的任意i,如果s中的 前i个字母和接下来的i个字母 相等 ,删除 前i个字母。
例如,如果 s = "ababc" ,那么在一步操作中,你可以删除 s 的前两个字母得到 "abc" ,因为 s 的前两个字母和接下来的两个字母都等于 "ab" 。
返回删除 s 所需的最大操作数。
示例 1:
输入:s = "abcabcdabc" 输出:2 解释: - 删除前 3 个字母("abc"),因为它们和接下来 3 个字母相等。现在,s = "abcdabc"。 - 删除全部字母。 一共用了 2 步操作,所以返回 2 。可以证明 2 是所需的最大操作数。 注意,在第二步操作中无法再次删除 "abc" ,因为 "abc" 的下一次出现并不是位于接下来的 3 个字母。
示例 2:
输入:s = "aaabaab" 输出:4 解释: - 删除第一个字母("a"),因为它和接下来的字母相等。现在,s = "aabaab"。 - 删除前 3 个字母("aab"),因为它们和接下来 3 个字母相等。现在,s = "aab"。 - 删除第一个字母("a"),因为它和接下来的字母相等。现在,s = "ab"。 - 删除全部字母。 一共用了 4 步操作,所以返回 4 。可以证明 4 是所需的最大操作数。
示例 3:
输入:s = "aaaaa" 输出:5 解释:在每一步操作中,都可以仅删除 s 的第一个字母。
提示:
1 <= s.length <= 4000s仅由小写英文字母组成
这类题,应该很容易想到动态规划或者记忆化搜索。也就是说,对于删除过程中产生的每一个字符串,我们都找到所有可能的删除点,然后执行操作。用记搜或者DP找出最大值。由于删除操作删除的一定是前缀,过程中最多产生s.size()个字符串,这是O(N)。再考虑对每个字符串操作的复杂度,可以看到,s.length最大可以到4000,这意味着最多容许O(N^2)的时间复杂度,也就是说,每个字符串找删除点的过程,必须是O(N)的。
考虑找删除点的过程。朴素的思路是遍历前缀,并逐个判断它和后面size长度的字符串是否相等。可是,这样不断切片比较的复杂度是O(N^2),不符合O(N)的要求。而KMP算法可以帮助我们在O(N)的时间复杂度内找到所有删除点。我们只需要善用next数组。
举个例子,考虑aabaab的删除点:可以删掉第一个a,也可以删掉aab。而第二种删除方案,实际上也可以视为前缀相继出现了两次。也就是说,基于next数组的意义——最长公共前后缀,如果最长公共前后缀恰好相连,不就是前缀相继出现了两次嘛。那么,映射到next数组上,也就是j=2next[j],就可以从next[j]开始截取。(这里采用的是不添加哨兵的方法,添加哨兵只需拿这个例子推一下)。需要注意的是,我们得在最后添加空格,使整个字符串都被遍历到。
我们求出它的next数组和截取位置如图

由于求next数组是O(N)的,所以求删除点也是O(N)的,这就满足了要求。
接着,可以利用DP和记搜分别写出代码,以长度为键即可。
记忆化搜索代码
1 | //记忆化搜索+KMP求删除点 |
动态规划代码
1 | //KMP求删除点+DP |
10.7更新
新遇到的KMP练习题
不用kmp也行的
28. 找出字符串中第一个匹配项的下标 - 力扣(LeetCode)
只要KMP模板+简单推理的
1316. 不同的循环子字符串 - 力扣(LeetCode)







